
documentation


This tutorial page shows you how to use the VisionLib Auto Initialization feature.
Note: This feature is still beta, and might be modified in upcoming releases.
In the past, most applications that were made with VisionLib Model Tracking started with a fix initial pose, to which the user had to align the physical object. There was still the possibility to save init data during the session and load it again, which enabled the user to gain some kind of static auto initialization.
While this workflow is still available however, it has disadvantages: it requires to collect such data manually in advance, it is not stable over time and is not robust against any other device rotation, object movement or changing surroundings compared to the recording.
With the new auto initialization, you can define your working area - which is called WorkSpace - and enable an initialization from any point in this area. Theses poses can be "trained" at the start of the application.
This way, you don't need to align the camera view to a certain pose anymore and start the tracking much faster and a lot easier: simply point your camera at the object and it will be recognized and tracked.
The concept of WorkSpaces in VisionLib is a key feature for multiple use cases in future versions:
Note: The AutoInit feature, as described here, is a pure on-device feature and does not connect to any learning service outside of the device. It will not and never send your data anywhere.
AutoInit might get performance-intensive and can thus cause problems on older hardware. We recommend using hardware from 2018 or newer.
Note: Test your tracking target with the SimpleModelTracking first and adjust the tracking parameters accordingly. Only proceed with this experimental feature as soon as the standard tracking is working fine.
You can find an example implementation of WorkSpaces in the AutoInitTracking scene from the VisionLib/Examples/ModelTracking/AutoInit folder.
In your own scene, drag the VLWorkSpace and VLWorkSpaceManager prefab from VisionLib/Utilities/Prefabs/AutoInit into the hierarchy. You can use multiple VLWorkSpaces but only one VLWorkSpaceManager in your scene.
If you like, you can now remove the VLInitCamera from your scene, or keep it to provide a "fallback" init pose.
The VLWorkSpace prefab consists of the parent object with some general settings:
And it contains the Origin and the Destination geometry as children, which define your area of interaction.
Therefore, the WorkSpace describes a set of possible views from the user on the object which are generated by "looking" from all origin points to all destination points.
The calculated number of poses will be shown in the inspector when selecting the VLWorkSpace, as seen in the picture below.
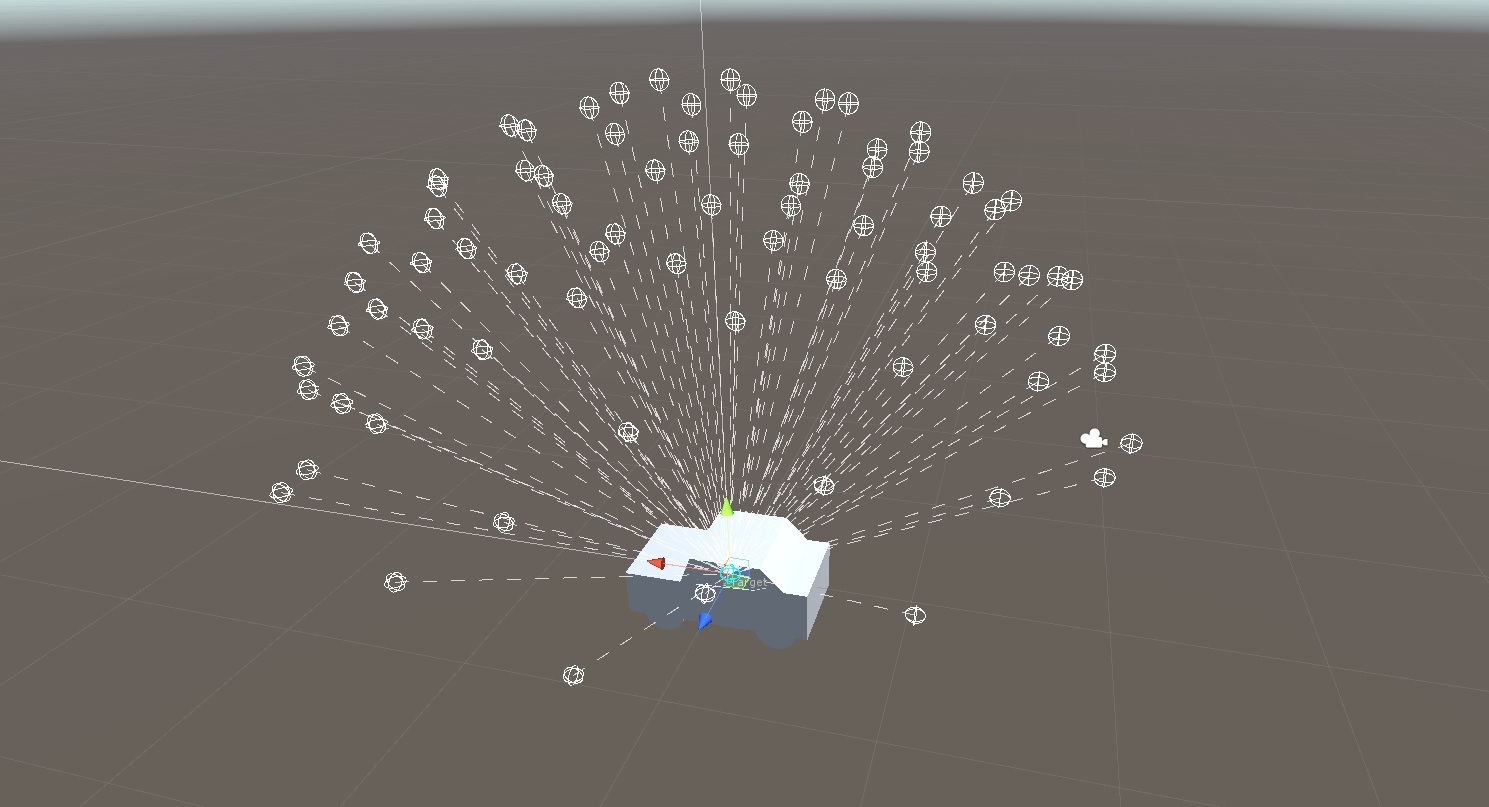
WorkSpaces can be represented geometrically by multiple predefined shapes. Suitable WorkSpace definitions can be saved as prefabs for reuse.
To achieve a custom parameterization, select the origin or destination geometry (children of the VLWorkSpace prefab) to modify its parameters in the inspector.
You can choose between four shapes: sphere, plane, line and point. Besides the width, length, radius and so on you can adjust the detail level or step of each shape, which later affects the number of initial poses to be learned.
The sphere has some special parameters in addition to the radius:
| Parameter | Default Value | Function |
|---|---|---|
| Detail Level | 0.1 | Amount of Pose Points |
| Vertical Angle Constraints (Polar): | ||
| Polar Start | 0° | Vertical starting angle |
| Polar Length | 90° | Vertical sweep angle size |
| Horizontal Angle Constraints (Azimuthal): | ||
| Azimuth Start | 0° | Horizontal starting angle |
| Azimuth Length | 360° | Horizontal sweep angle size |
In the VLWorkSpace prefab, the default origin geometry is set to a half sphere, with PolarStart at 0° and PolarLength at 90°. This is a good preset for objects that stand or lie on a surface and should be initialized from above. Other custom variations (e.g. spherical triangle) can be achieved by constraining the horizontal angles as well.
If the WorkSpace geometry configuration is adequate, place it over the tracking target via Unity's transformation component. The WorkSpace and its origin & destination geometry can be translated and rotated.
Note: The scale of the WorkSpace and its geometries cannot be changed at the moment! Always keep it at (1,1,1).
Important: Keep in mind that the pose amount in the VLWorkSpace object depends on the detail level or step count that you defined in the geometry. As a rule of thumb, a higher amount of poses enables more initialization points but also increases the initial pose learning time and might affect the performance negatively. A decreased performance can overall lead to a slower initialization!
That said, it is always better to only set up initialization areas that are actually needed.
Here you can either use the Destination GameObject, which is a child of the VLWorkSpace, and adjust it similar to how you used the Origin. In most cases, it will be enough to use only one target point.
Or you can simply drag your tracking target object from the hierarchy inside this public parameter. In that case, the geometric center of the GameObject will be used as a single target point.
Note: When using a GameObject as destination, the transform of this object must lie in the origin (0,0,0) of the scene.
Note: If a destination point shares its position with an origin point, it won't be possible to create a corresponding initialization pose.
To preview the poses, that you generated by setting the origin geometry and destination object, you can use the following:
See the gizmos in scene view:
VLWorkSpace is selectedshowLines parameter of the VLWorkSpace to show dotted lines from origin to destination points in scene view. To keep the scene tidy, they will only be drawn if the number of poses is smaller than a fix maximum.Preview poses in camera:
VLWorkSpace to preview the generated poses in your game view (make sure you can see the game view window in Unity)The VLWorkSpaceManager is mandatory and aggregates one or more VLWorkSpace definitions to process them during runtime.
It contains the following public parameters:
As always, reference your used tracking configuration (.vl file) and license in the VLTrackingConfiguration component of the VLTracking object. To enable AutoInit, insert "autoInit": true in your tracking configuration:
Note: You can delete the "initPose" section from your tracking configuration, or keep it to provide a "fallback" pose.
The last step is to activate the pose learning. Do that either by using the autostart option in the VLWorkSpaceManager(which is active by default), or by calling the following function e.g. on a button click or from your script: VLWorkSpaceManager.LearnWorkSpaceInitData()
Wait some seconds (activate the progress bar in the VLWorkSpaceManager to show the learning progress) until all poses have been trained.
Now you can point your camera to the physical object from a direction that is included in the VLWorkSpace that you defined and it will be tracked.
The footprint of the learned data is quite small (several 100kB) and will be cached in local-storage-dir:/VisionLib/AutoInit/initData_filename.binz. The filename is a combination of the hash of your WorkSpace definition and model definition.
You only need to "train" the WorkSpaces once. When you call the learning command a second time with the same WorkSpace definition and model configuration (including transforms and model-constellation), the cached file will be used instead of relearning.
To stop AutoInit or reset its learned data on runtime, you need to call VLModelTrackerBehaviour_v1.ResetInitData(). In the example scene, the Clear button is using this command.
This will not delete the cache, which thus can be loaded again without relearning (e.g. by pressing the Learn button in the example scene).
If you want to force a relearning of the poses, you will need to remove the .binz file from the local storage of your device.
AutoInit is not working as expected? Check the following:
You can add some optional parameters for AutoInit by inserting it as a section in your tracking configuration:
The following optional parameters are available:
| Parameter | Type | Default Value | Function |
|---|---|---|---|
| laplaceThreshold | float | laplaceThreshold of ModelTracker * 4 | See ModelTracker laplaceThreshold |
| normalThreshold | float | normalThreshold of ModelTracker | See ModelTracker normalThreshold |
| writeDebug | bool | false | If set to true, the vlSDK will write images of the renderings (that are an intermediate step when learning features for AutoInit) to the writeDebugPath. The debug images are especially helpful to understand the effects of laplaceThreshold and normalThreshold to the edge extraction. |
| writeDebugPath | string | "local-storage-dir:/VisionLib/AutoInit/DebugImages/EdgeImage_" | Path for writing debug images. The default path writes images to local-storage-dir:/VisionLib/AutoInit/DebugImages_[n]/EdgeImage_[m].png |
| cacheDir | string | "local-storage-dir:/VisionLib/AutoInit/" | The directory in which the cached AutoInit learning results will be stored. |
When troubleshooting, it might be helpful to activate "writeDebug":true in your tracking configuration.
Have a look at the generated images. Your object should be fully visible and lie in the center of the image. If not, adjust your WorkSpace parameters in Unity.
If the white lines in the images are dotted or messy in some way, you can modify the laplaceThreshold and normalThreshold of the autoInit section to get better results. Usually you will need to take a much higher float value than for the corresponding parameters of the model tracker. If the debug images have clear, tidy lines, the set parameters are fine.
See an example for debug images with good and bad lines below:

If your written debug images show your model rotated, you should adjust the up vector of your WorkSpace.

Currently, AutoInit works well on objects that are initialized in a long shot view. Thus, smaller objects which fit into the camera view completely will work much better.
You can check if the object is fully visible in the camera preview. If you are unsure, increase the distance from the VLWorkSpace origin points to the target object.
Close-Up object initialization is still under development, but might already work with the tools provided in this version.
Note: On HoloLens 2, it can make a great difference to set "fieldOfView: narrow" when working with small objects. For more details on that parameter, please refer to HoloLens Optimizations.
This is a legit question. Anyway, initializing the tracking from all views might not be necessary and restricting the working area will help VisionLib to find the object more reliably.
Also, you should prevent the definition of views, from where the object is not even recognizable or distinguishable by its form: Initializing a cell phone from the side will probably result in detecting a pencil as well.
So please consider this when defining WorkSpaces.
Please contact us and we can help you find a way to integrate WorkSpaces into your product.
We are happy if you give us feedback or even provide us image sequences of objects being initialized.
If you have issues or suggestions on how to enhance or integrate this feature, please do not hesitate to contact us on request@visionlib.com.